Above is a successful code edit by Aider. You can see the results running in a browser at this link. Until Aider fixed it the theme drop down was non-functional. This is using Qwen3-14B-Q6_K running on Llama.cpp which was modified by me to implement Turbo Quant.
Javascript is easy though ! I’ll add a more in depth example later.
The results are very interesting. So far simple edits are functional. But much more extensive development of larger code bases with a long context may not be here yet. Although that may happen sooner than we think ! Turbo Quant is now being applied to the model itself by various projects ! So 27B models can be shrunk down to fit on a 16gb GPU.
But its not just model size. It’s speed. With a local model on my consumer level GPU thinking is quite slow compared to the big data centre cloud models. This makes sense as those models are often split across multiple GPU’s running in parallel.
So a full production, professional coding environment may not yet be possible. But this testing shows that is coming down the line very fast !
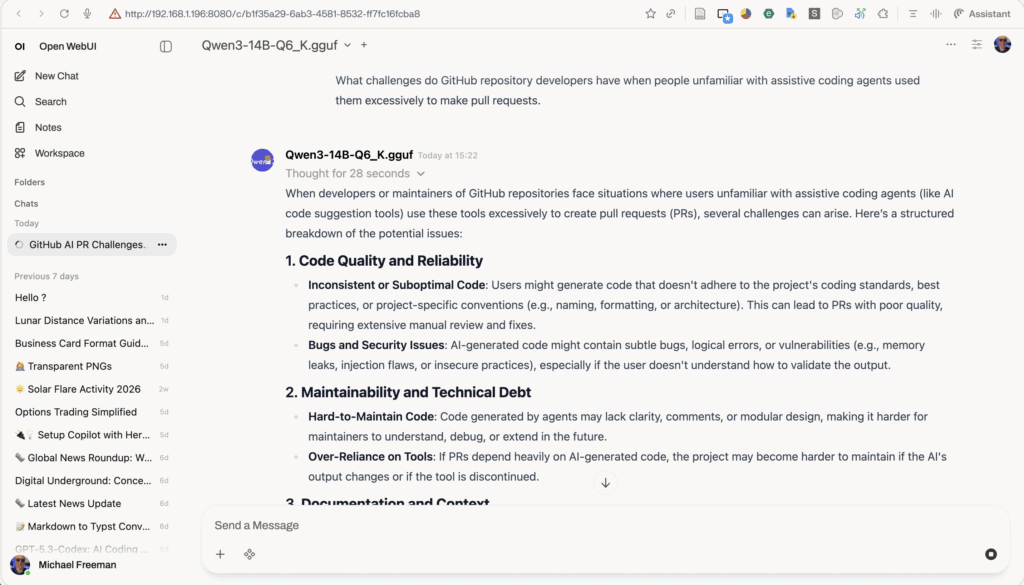
But my approach is pragmatic one. First I needed to verify the viability of a full coding environment. Secondly its determining what can be used locally. Not every useful AI task needs some huge data centre or £10,000 of local GPU’s. So far Qwen3-14B-Q6_K seems a lot more viable as a chat AI with web search capability through Open WebUI. In fact here it is in action …
Leave a Reply